|
I am a researcher at ByteDance working on Generative AI. Previously, I was a senior research scientist at Tencent. I earned my Ph.D. from École Polytechnique Fédérale de Lausanne (EPFL) in 2021 under the supervision of Prof. Pascal Fua, following a Master's degree from EPFL in 2017 and a Bachelor's degree from the University of Electronic Science and Technology of China (UESTC) in 2014. Email / CV / Google Scholar / LinkedIn / Twitter |

|
|
My research interests lie in the field of Computer Vision, Machine Learning and Robotics. My current focus is generative model and 3D vision. Before that, I worked on developing algorithms to crowd analysis problem, including counting, localization and motion estimation. I also worked on video understanding, action recognition, semantic segmentation, domain adaptation and learning with less supervision. |
|
|
| * indicates equal contribution, † represents project lead and & denotes corresponding author. |
 |
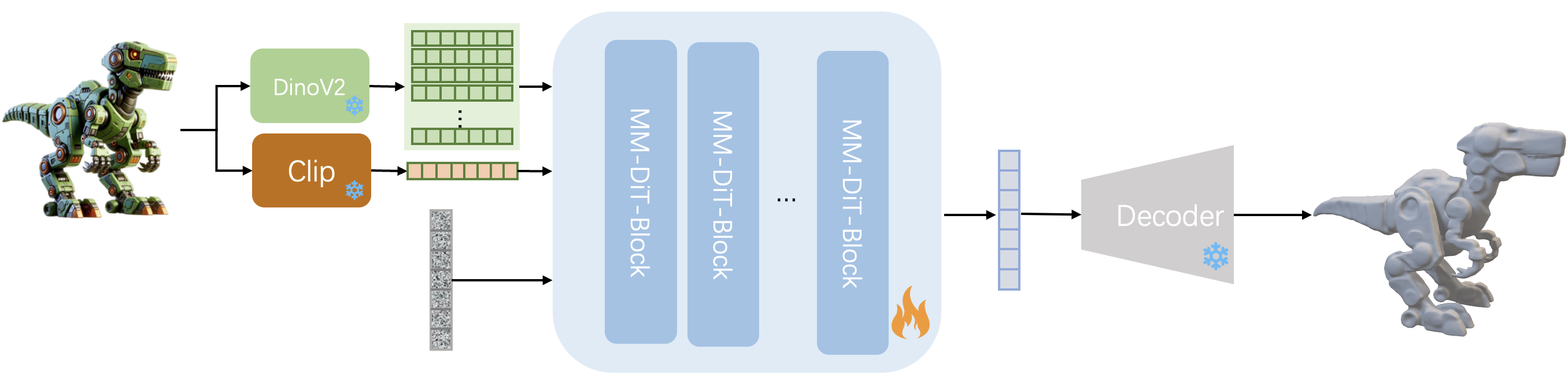
Weizhe Liu*, Yunjie Wu*, Xiangqian Shu, Guangwei Wang, Xiangyu Xu, Peng Li, Yujie Li, Hengkai Guo† Tech Report , 2026 project page/ pdf We present DreamCharacter-1, a lightweight post-adaptation framework that calibrates pretrained 3D foundation models toward high-fidelity, production-ready 3D character generation. Building upon a frozen 3D foundation backbone, our pipeline incorporates geometry post-training, texture post-training, and inference acceleration. Extensive experiments demonstrate that DreamCharacter-1 produces visually compelling and structurally robust 3D character assets, consistently surpassing state-of-the-art character generation methods. |
 |
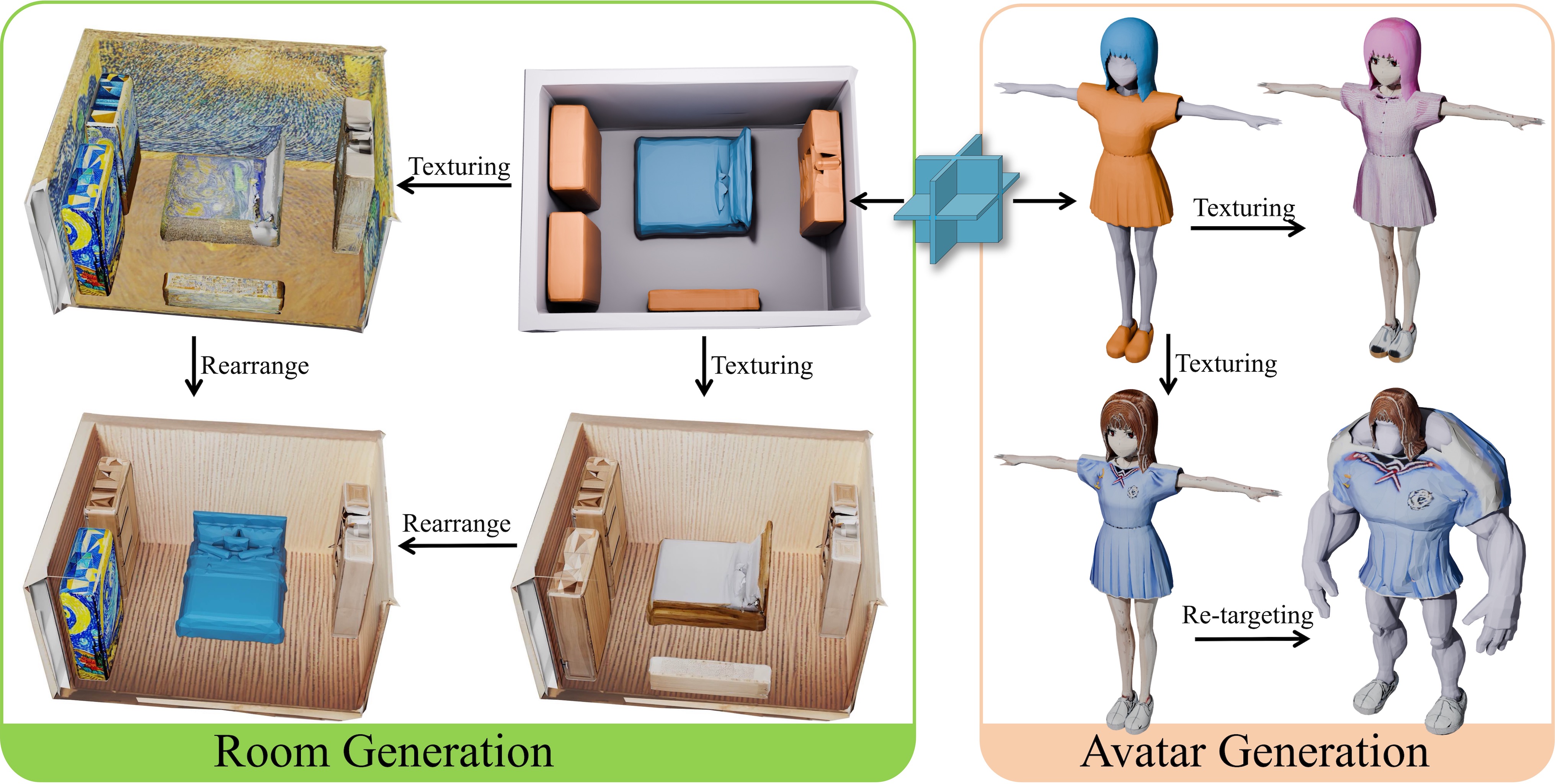
Jiayu Yang*, Taizhang Shang*, Weixuan Sun*, Xibin Song*, Ziang Chen*, Senbo Wang*, Shenzhou Chen*, Weizhe Liu*, Hongdong Li, Pan Ji Tech Report , 2025 pdf/ code This report presents a comprehensive framework for generating high-quality 3D shapes and textures from diverse input prompts, including single images, multi-view images, and text descriptions. This report details the system architecture, experimental results, and potential future directions to improve and expand the framework. |
 |
Jingnan Gao, Weizhe Liu †, Weixuan Sun, Senbo Wang, Xibin Song, Taizhang Shang, Shenzhou Chen, Hongdong Li, Xiaokang Yang, Yichao Yan, Pan Ji arXiv preprint , 2025 In this paper, we introduce MARS, a novel approach for 3D shape detailization. Our method capitalizes on a novel multi-LOD, multi-category mesh representation to learn shape-consistent mesh representations in latent space across different LODs. |
 |
Ruikai Cui, Xibin Song, Weixuan Sun, Senbo Wang, Weizhe Liu, Shenzhou Chen, Taizhang Shang, Yang Li, Nick Barnes, Hongdong Li, Pan Ji Neural Information Processing Systems (NeurIPS) , 2024 Large Reconstruction Models have made significant strides in the realm of automated 3D content generation from single or multiple input images. Despite their success, these models often produce 3D meshes with geometric inaccuracies, stemming from the inherent challenges of deducing 3D shapes solely from image data. In this work, we introduce a novel framework, the Large Image and Point Cloud Alignment Model (LAM3D), which utilizes 3D point cloud data to enhance the fidelity of generated 3D meshes. |
 |
Han Yan, Yang Li, Zhennan Wu, Shenzhou Chen, Weixuan Sun, Taizhang Shang, Weizhe Liu, Tian Chen, Xiaqiang Dai, Chao Ma, Hongdong Li, Pan Ji SIGGRAPH Asia, 2024 video/ pdf/ code We present Frankenstein, a diffusion-based framework that can generate semantic-compositional 3D scenes in a single pass. Unlike existing methods that output a single, unified 3D shape, Frankenstein simultaneously generates multiple separated shapes, each corresponding to a semantically meaningful part. The 3D scene information is encoded in one single tri-plane tensor, from which multiple Singed Distance Function (SDF) fields can be decoded to represent the compositional shapes. |
 |
Ruikai Cui, Weizhe Liu &, Weixuan Sun, Senbo Wang, Taizhang Shang, Yang Li, Xibin Song, Han Yan, Zhennan Wu, Shenzhou Chen, Hongdong Li, Pan Ji The European Conference on Computer Vision (ECCV), 2024 project page/ pdf/ code 3D shape generation aims to produce innovative 3D content adhering to specific conditions and constraints. Existing methods often decompose 3D shapes into a sequence of localized components, treating each element in isolation without considering spatial consistency. As a result, these approaches exhibit limited versatility in 3D data representation and shape generation, hindering their ability to generate highly diverse 3D shapes that comply with the specified constraints. In this paper, we introduce a novel spatial-aware 3D shape generation framework that leverages 2D plane representations for enhanced 3D shape modeling. |
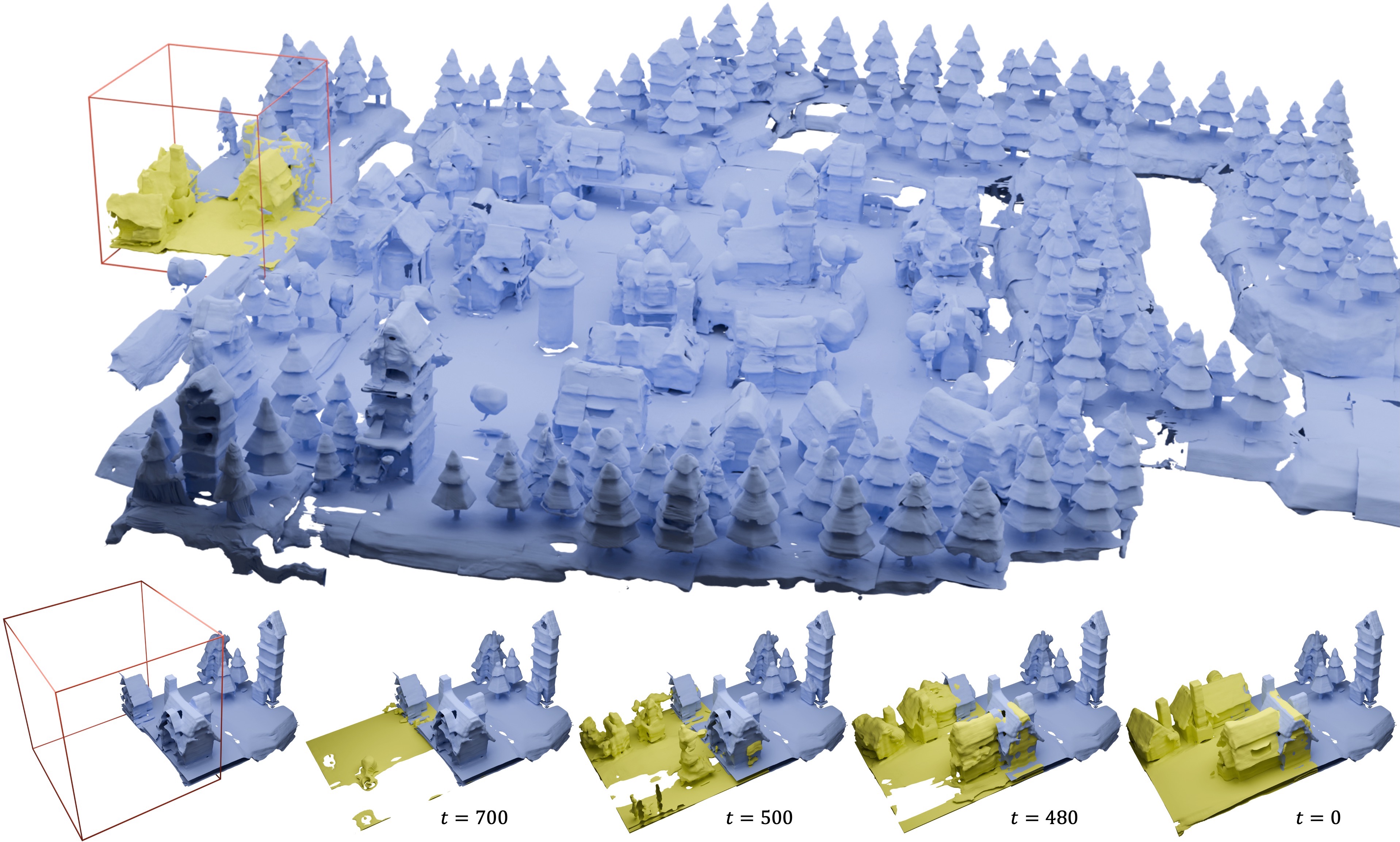 |
Zhennan Wu, Yang Li, Han Yan, Taizhang Shang, Weixuan Sun, Senbo Wang, Ruikai Cui, Weizhe Liu, Hiroyuki Sato, Hongdong Li, Pan Ji ACM Transactions on Graphics (SIGGRAPH), 2024 project page/ pdf/ code We present BlockFusion, a diffusion-based model that generates 3D scenes as unit blocks and seamlessly incorporates new blocks to extend the scene. BlockFusion is trained using datasets of 3D blocks that are randomly cropped from complete 3D scene meshes. Through per-block fitting, all training blocks are converted into the hybrid neural fields: with a tri-plane containing the geometry features, followed by a Multi-layer Perceptron (MLP) for decoding the signed distance values. |
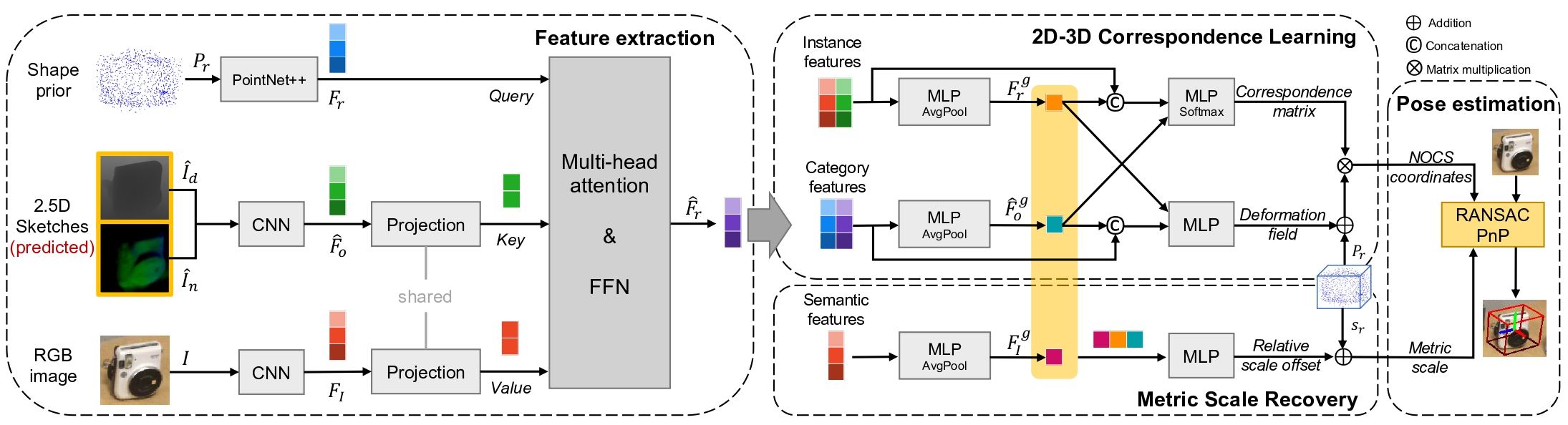 |
Jiaxin Wei, Xibin Song, Weizhe Liu, Laurent Kneip, Hongdong Li, Pan Ji IEEE International Conference on Robotics and Automation(ICRA), 2023 pdf/ code While showing promising results, recent RGB-D camera-based category-level object pose estimation methods have restricted applications due to the heavy reliance on depth sensors. RGB-only methods provide an alternative to this problem yet suffer from inherent scale ambiguity stemming from monocular observations. In this paper, we propose a novel pipeline that decouples the 6D pose and size estimation to mitigate the influence of imperfect scales on rigid transformations. |
 |
Martin Engilberge, Weizhe Liu, Pascal Fua IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023 pdf/ code Multi-view approaches to people-tracking have the potential to better handle occlusions than single-view ones in crowded scenes. They often rely on the tracking-by-detection paradigm, which involves detecting people first and then connecting the detections. In this paper, we argue that an even more effective approach is to predict people motion over time and infer people's presence in individual frames from these. This enables to enforce consistency both over time and across views of a single temporal frame. We validate our approach on the PETS2009 and WILDTRACK datasets and demonstrate that it outperforms state-of-the-art methods. |

|
Weizhe Liu, Bugra Tekin, Huseyin Coskun, Vibhav Vineet, Pascal Fua, Marc Pollefeys The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 pdf/ code In this paper, we propose an approach to align sequential actions in the wild that involve diverse temporal variations. To this end, we propose an approach to enforce temporal priors on the optimal transport matrix, which leverages temporal consistency, while allowing for variations in the order of actions. Our model accounts for both monotonic and non-monotonic sequences and handles background frames that should not be aligned. We demonstrate that our approach consistently outperforms the stateof-the-art in self-supervised sequential action representation learning on four different benchmark datasets. |
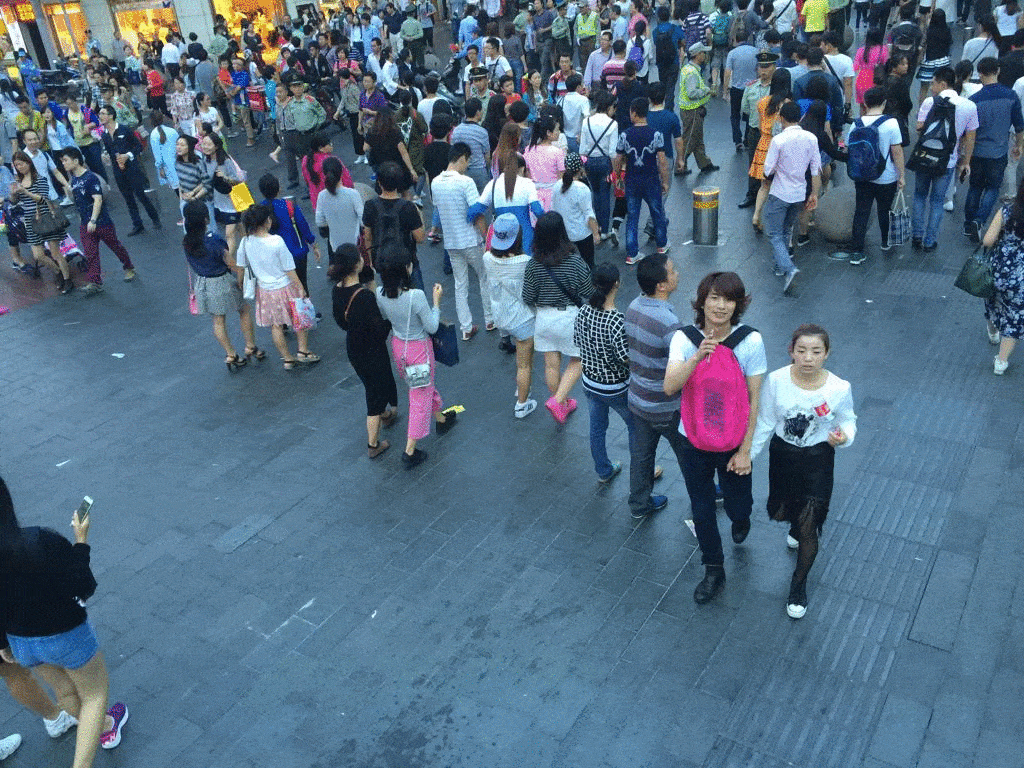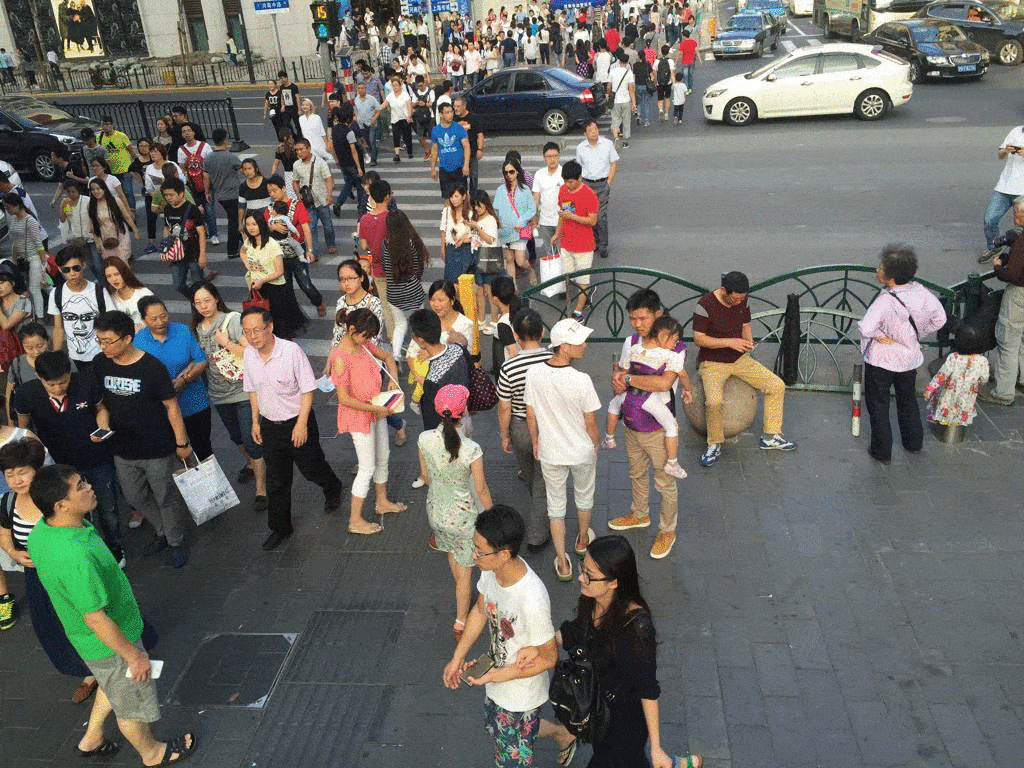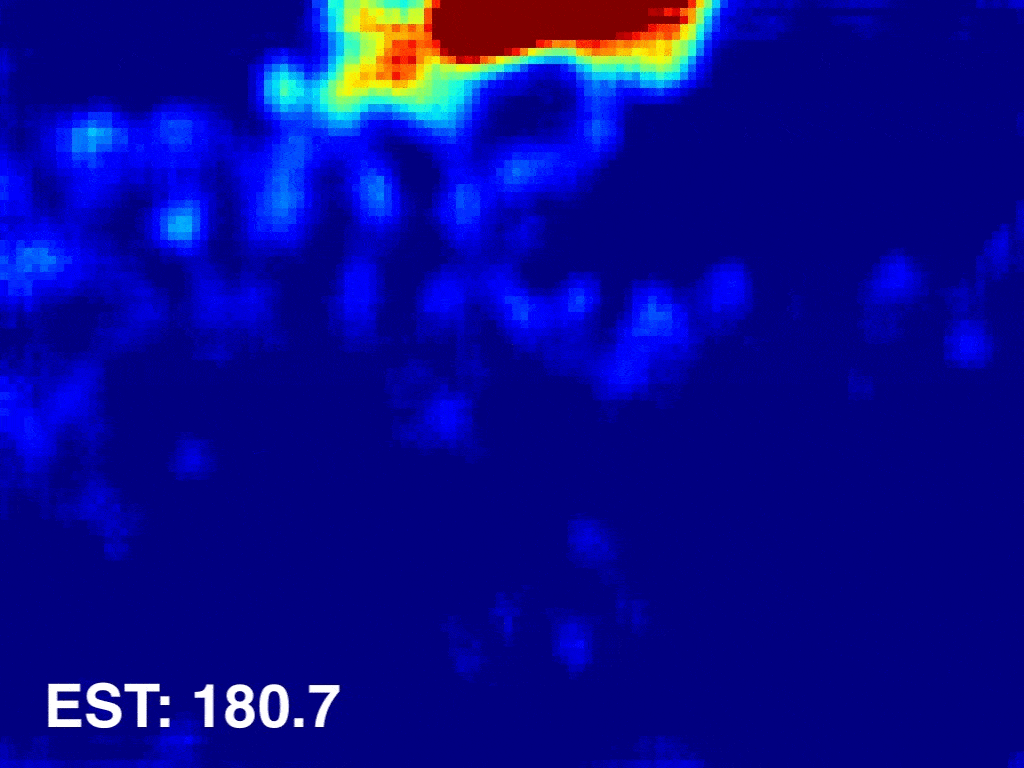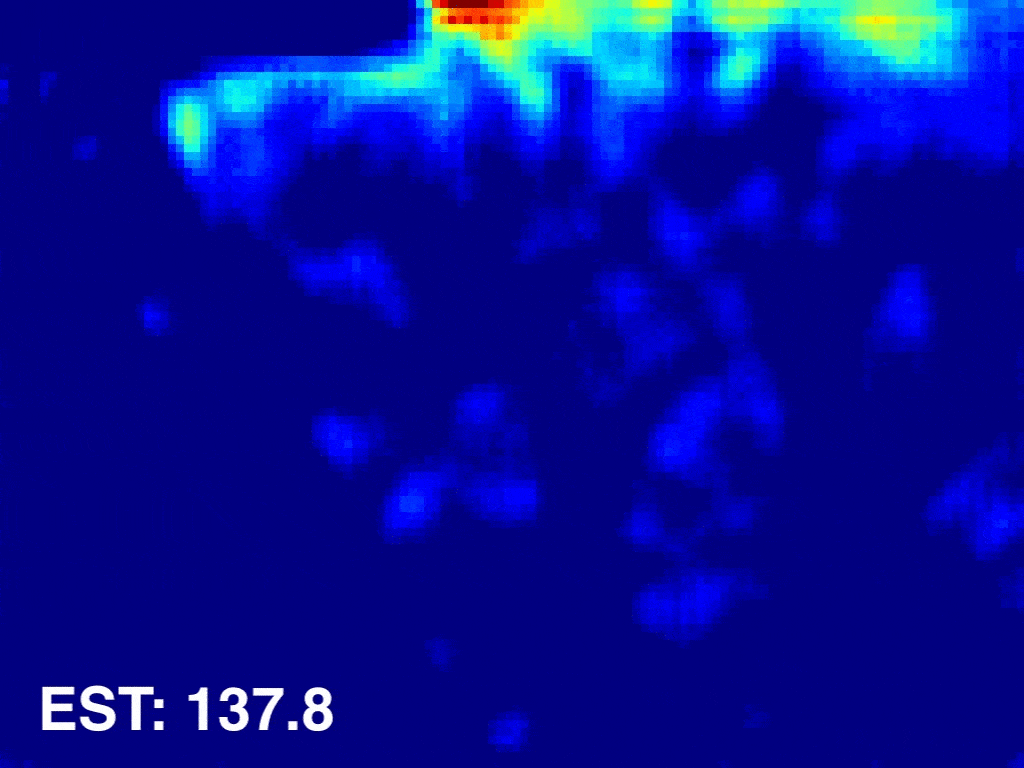
|
Weizhe Liu, Nikita Durasov, Pascal Fua The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (Oral) pdf/ code In this paper, we train with both synthetic images, along with their associated labels, and unlabeled real images. To this end, we force our network to learn perspective-aware features by training it to recognize upside-down real images from regular ones and incorporate into it the ability to predict its own uncertainty so that it can generate useful pseudo labels for fine-tuning purposes. This yields an algorithm that consistently outperforms state-of-the-art cross-domain crowd counting ones without any extra computation at inference time. |

|
Weizhe Liu, Mathieu Salzmann, Pascal Fua IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021 pdf / press / video / code In this paper, we advocate estimating people flows across image locations between consecutive images and inferring the people densities from these flows instead of directly regressing them. This enables us to impose much stronger constraints encoding the conservation of the number of people. As a result, it significantly boosts performance without requiring a more complex architecture. Furthermore, it allows us to exploit the correlation between people flow and optical flow to further improve the results. We also show that leveraging people conservation constraints in both a spatial and temporal manner makes it possible to train a deep crowd counting model in an active learning setting with much fewer annotations. This significantly reduces the annotation cost while still leading to similar performance to the full supervision case. |
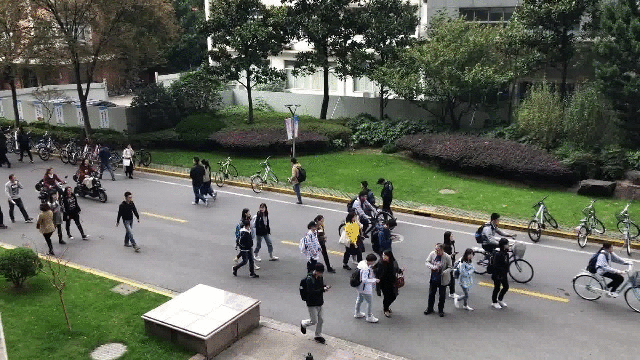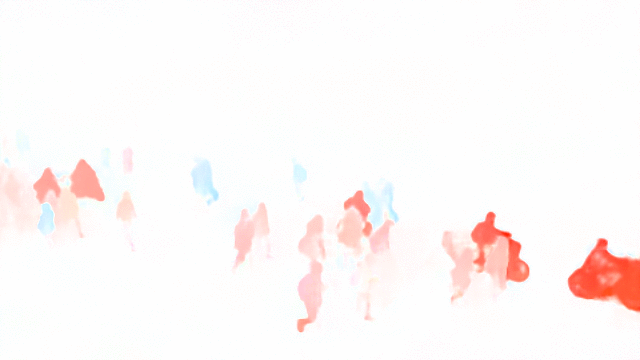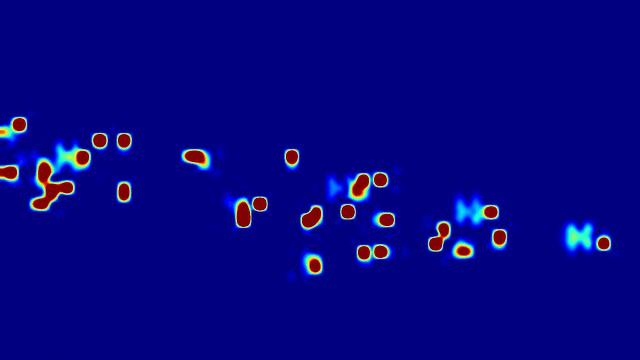
|
Weizhe Liu, Mathieu Salzmann, Pascal Fua The European Conference on Computer Vision (ECCV), 2020 pdf / press / video / code In this paper, we advocate estimating people flows across image locations between consecutive images and inferring the people densities from these flows instead of directly regressing. This enables us to impose much stronger constraints encoding the conservation of the number of people. As a result, it significantly boosts performance without requiring a more complex architecture. Furthermore, it also enables us to exploit the correlation between people flow and optical flow to further improve the results. |

|
Weizhe Liu, Krzysztof Lis, Mathieu Salzmann, Pascal Fua The IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019 pdf / press / video In this paper, we explicitly model the scale changes and reason in terms of people per square-meter. We show that feeding the perspective model to the network allows us to enforce global scale consistency and that this model can be obtained on the fly from the drone sensors. In addition, it also enables us to enforce physically-inspired temporal consistency constraints that do not have to be learned. This yields an algorithm that outperforms state-of-the-art methods in inferring crowd density from a moving drone camera especially when perspective effects are strong. |

|
Weizhe Liu, Mathieu Salzmann, Pascal Fua The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019 pdf / press / video / code In this paper, we introduce an end-to-end trainable deep architecture that combines features obtained using multiple receptive field sizes and learns the importance of each such feature at each image location. In other words, our approach adaptively encodes the scale of the contextual information required to accurately predict crowd density. This yields an algorithm that outperforms state-of-the-art crowd counting methods, especially when perspective effects are strong. |
|
Reviewer of major computer vision conferences (CVPR, ICCV, ECCV) and journals (TPAMI, IJCV, TIP). |
|
|
|
|